
Sometimes, debugging a failing CI job is a lot like being a mechanic.
Picture this: you walk up to a car that won’t work as expected. What’s wrong? Dead battery? A radiator leak? A faulty ignition switch? You poke and prod from the outside, but until you’ve popped the hood, all you can do is guess and hope for the best.
CI is no different. A job fails. Is a flaky test to blame? Did the VM run out of memory? Or is it something else entirely? To really know, you need to pop the hood. Without real access, you’re stuck troubleshooting in the dark. Relying on logs, at best.
So, we built an SSH feature. It’s our way of popping the hood on our running CI jobs. Behind the scenes, this feature relies on three subsystems — network tunneling, DNS registration, and SSH key management — each designed to tackle different quirks in the VM lifecycle.
To start with, I’ll admit that we’re a bit of an odd duck. We’re an infrastructure provider that doesn’t run on AWS (more on that another time). Instead, our hardware lives in ISO 27001 data centers around the world. Every one of our hundreds of bare-metal hosts runs a single agent. This process is responsible for managing VM lifecycles. So, naturally, it made sense for this same process to manage all host networking required to reach each VM, too.
How? iptables.
Using just a few iptables commands, we can control how network traffic is routed between the outside world and a VM. This lays the foundation for safely connecting external users to the correct VM. In fact, it only takes three iptables commands to make it happen:
This first command intercepts incoming connections to a specific host port, and rewrites the destination to a specific VM’s internal IP and SSH port. The setting of this command follows an earlier process that picks an available host port per VM from a reserved range for port-forwarding the VM’s SSH port.
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport <hostPort> -j DNAT --to-destination <vmIP>:22After redirection, it’s necessary to permit the forwarded packets from the host to the VM. Without this acceptance, the VM would not receive the incoming SSH connection, blocking access:
iptables -A FORWARD -i eth0 -d <vmIP> -p tcp --dport 22 -j ACCEPTFinally, when the VM responds to the external user, masquerading the packets makes them appear as if they’re coming from the host, hiding the VM’s internal address:
iptables -t nat -A POSTROUTING -s <vmIP> -p tcp --sport 22 -j MASQUERADEWith us running many VMs simultaneously per host, and thousands of VMs over the course of a day, these network rules could quickly become unmanageable. To prevent any sort of chaos, we manage these rules in a structured way. Every iptables rule added during VM creation is removed on VM purge. This happens even if the VM crashes. But more importantly, we apply these rules transactionally. If any operation in the rule setup sequence fails, all prior rules are rolled back, ensuring no network rule orphans.
With dynamic port allocation and network rules for port forwarding to the right VM in place, the next challenge is making connections as seamless and human-friendly as possible. This is where some DNS magic steps in.
I strongly believe in designing from the developer’s desired experience and working backward. That principle led me to start with some basic market research. As I surveyed existing solutions, one thing quickly stood out: forcing users to connect with awkward IP:port strings like ssh user@34.123.45.667.222 just wasn’t a great experience. Instead, I wanted something predictable, human-friendly — think ssh vm-123.vm.blacksmith.sh. But to get this, we’d need to pull off a little DNS magic.
DNS comes with inherent propagation delays. Even when a brand-new, unique hostname is created for a VM, it can take minutes before that record becomes resolvable worldwide. In our CI environment, where VMs are short-lived and ephemeral, this delay was unacceptable. We needed hostnames to be discoverable instantly.
Our big idea was to operate our own DNS service with a custom CoreDNS plugin, backed by a heavily customized Redis plugin that supports multiple backends with automatic failover handling (and yes, we have plans to open-source this). We then delegate resolution of all VM hostnames to this DNS service through Cloudflare. At startup, our CoreDNS plugin queries all Redis backends in parallel, mapping out every available DNS zone.
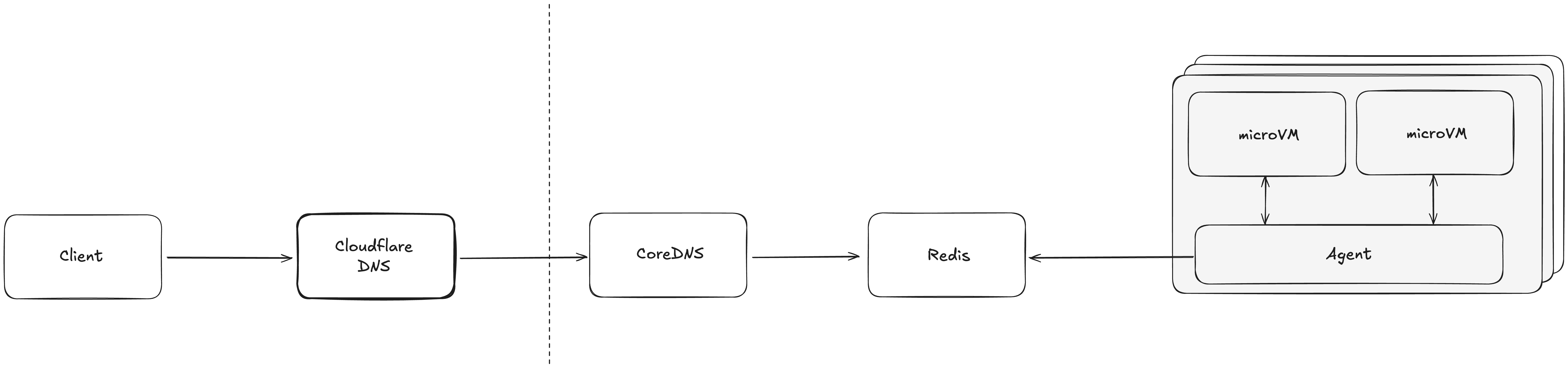
As a result, when a new VM is created, its hostname is immediately registered in Redis. And any VM registered in any Redis backend will immediately appear in the global DNS view, making it discoverable worldwide. We now have a way to manage DNS records in real-time rather than waiting for it to propagate.
While a memorable hostname is great, it isn’t enough without the right credentials. That's why we also need a way to control who gets access.
We need to inject SSH metadata into the VM at creation. Otherwise, the correct GitHub user won’t be able to access the VM. To do that, we leverage GitHub Actions hooks for lifecycle management.
We start by dynamically fetching SSH keys straight from GitHub’s API, triggered on-demand by the workflow itself. With this approach, we ensure we’re using sender-specific keys, so only the GitHub users who initiated the workflow can SSH into the VM.
Beyond secure access, there’s the matter of the actual debugging experience. We’ve known since we started this project that debugging a running CI job would be much easier for users if we could delay tearing down the VM running the job. Normally, we tear it down as soon as the job ends. That works most of the time. But, imagine being a developer with an active SSH session in the middle of debugging a job. In an ideal world, we’d want a little grace period. That’s one reason we built a simple way to detect active SSH sessions:
# Check for active SSH sessions every 10 seconds
while [ $elapsed -lt $MAX_WAIT_SECONDS ]; do
if ss -tn state established '( sport = :22 )' | grep -q ':22'; then
has_ssh_sessions=true
sleep 10
else
# No sessions? Exit immediately
break
fi
doneWe give users exactly 4 minutes and 50 seconds of grace period if we detect any active SSH session to the VM. Why exactly 4 minutes and 50 seconds? Well, this logic runs in the Complete runner step at the end of every GitHub Actions job. Which is great, because this means VMs and their SSH access exist only during job execution. But after some trial and error, we later found out that GitHub has a 5-minute timeout for waiting on the job completion hook (undocumented, of course). So for now, 4 minutes and 50 seconds it is. That being said, we already have plans to make this configurable in the near future.

The end result? You can now pop the hood of any running CI job and everything’s ready to go. No VPNs. No port forwarding setup. No key management headaches. Instant, secure access — just like this:
# Your GitHub Action job starts
Run started. SSH access available:
ssh -p 38291 runner@vm-abc123.vm.blacksmith.sh
# You SSH in from anywhere
$ ssh -p 38291 runner@vm-abc123.vm.blacksmith.sh
Welcome to your GitHub Actions runner!
# Job completes, you have 4:50 to finish debugging
Job completed. SSH sessions active, waiting up to 4m50s...To learn more, check out our SSH docs.

